El Frankenstein metodológico: cuando la estadística responde otra pregunta

Por Maicel Monzon
Introducción
Lees un informe final de un ensayo clínico (CSR) o un artículo en una revista de alto impacto.
Todo parece correcto: objetivos claros, variables bien definidas, tablas limpias y un Plan de Análisis Estadístico (SAP) coherente.
Sin embargo, a veces ocurre algo más inquietante:
el estudio parece responder una pregunta…
pero no exactamente la que motivó el ensayo.
No se trata de un error aritmético ni de un p-hacking burdo.
Es algo más sutil: una desconexión entre el fenómeno clínico que se quería estudiar y el efecto que realmente se termina estimando.
A esta criatura la llamo el Frankenstein metodológico: una construcción hecha de piezas técnicamente correctas que, al ensamblarse, producen una inferencia distinta a la pretendida.
Casos históricos como rofecoxib (Vioxx) mostraron que un programa de ensayos puede generar señales convincentes en algunos análisis y, al mismo tiempo, ocultar riesgos relevantes.
Más allá del ejemplo concreto, la lección general es más amplia:
un análisis puede ser estadísticamente válido
y clínicamente engañoso
si no hay alineación entre pregunta, datos y método.
La idea central: desconexión inferencial
Llamo desconexión inferencial a la ruptura entre:
fenómeno clínico → pregunta científica → estimando → análisis estadístico
Cuando estas piezas no están alineadas, el estudio puede terminar respondiendo:
- otra pregunta,
- bajo otros supuestos,
- con implicaciones clínicas distintas,
sin que eso quede claramente explicitado en el informe.
En términos del marco ICH E9(R1), el problema no es solo “qué análisis se hizo”, sino:
qué efecto se terminó estimando realmente
y si ese efecto corresponde a la pregunta clínica original.
Qué es el Frankenstein metodológico
Definición operativa:
Existe un Frankenstein metodológico cuando el protocolo promete responder una pregunta clínica, pero el análisis final estima un efecto diferente debido al manejo de sucesos intercurrentes, datos faltantes o decisiones analíticas no alineadas con esa pregunta.
No implica fraude ni mala fe.
Suele surgir de procesos fragmentados:
- los clínicos formulan objetivos,
- los estadísticos implementan métodos,
- la ejecución introduce desviaciones,
- el informe conserva etiquetas formales (“ITT”, “primario”, “confirmatorio”),
pero nadie verifica si todo sigue apuntando a la misma pregunta.
Dónde nace el monstruo
1. De fenómeno clínico a variable
El clínico piensa en fenómenos: “mejorar la calidad de vida”,
“reducir exacerbaciones”, “prolongar la supervivencia”.
El análisis necesita:
- una variable,
- un tiempo,
- reglas ante abandonos,
- supuestos sobre lo no observado.
Si esa traducción no es explícita, la pregunta cambia sin que nadie lo declare.
2. El uso ritual de etiquetas
Expresiones como:
- “intención de tratar (ITT)”
- “análisis primario”
- “resultado principal”
funcionan a veces como amuletos metodológicos: tranquilizan, pero no explican.
En ensayos aleatorizados, ITT suele entenderse como “analizar según asignación aleatoria”.
Pero ¿qué significa eso cuando:
- hay rescates,
- hay discontinuaciones,
- hay datos faltantes informativos?
Sin reglas explícitas, la etiqueta no garantiza nada.
3. Significación estadística ≠ relevancia clínica
Un valor de p pequeño indica compatibilidad con un modelo nulo, no utilidad clínica.
Además, cuando una fracción relevante de los datos está ausente, la conclusión puede depender más de los supuestos que de los datos observados.
En ese escenario:
los análisis de sensibilidad no son opcionales:
son parte del resultado.
Anatomía del Frankenstein (vista general)
- Planificación: se promete un efecto (estimando) poco operacionalizado.
- Ejecución: aparecen sucesos intercurrentes y faltantes.
- Análisis: se elige una estrategia sin discutir su relación con la pregunta clínica.
- Reporte: se presenta un resultado “limpio” sin mostrar la distancia con lo que se quería estimar.
Este post se centra solo en una de esas posibles desconexiones:
datos faltantes y su impacto sobre el efecto estimado
(Caso 1 del sistema).
Caso práctico (reproducible): datos faltantes
Simulamos un ensayo con desenlace binario:
- 60 % de éxito en control
- 65 % en tratamiento
Introducimos datos faltantes no aleatorios:
en el grupo tratado, los no respondedores abandonan más.
La pregunta clínica implícita es:
“¿es mejor el tratamiento que el control?”
Pero la pregunta estadística efectiva depende de cómo tratemos lo no observado.
| Estrategia | Control | Tratamiento | Diferencia |
|---|---|---|---|
| Solo casos completos | 0.63 | 0.75 | 0.12 |
| Imputación simplista | 0.67 | 0.80 | 0.13 |
| Escenario pesimista | 0.67 | 0.60 | -0.07 |
Un solo conjunto de datos, tres historias
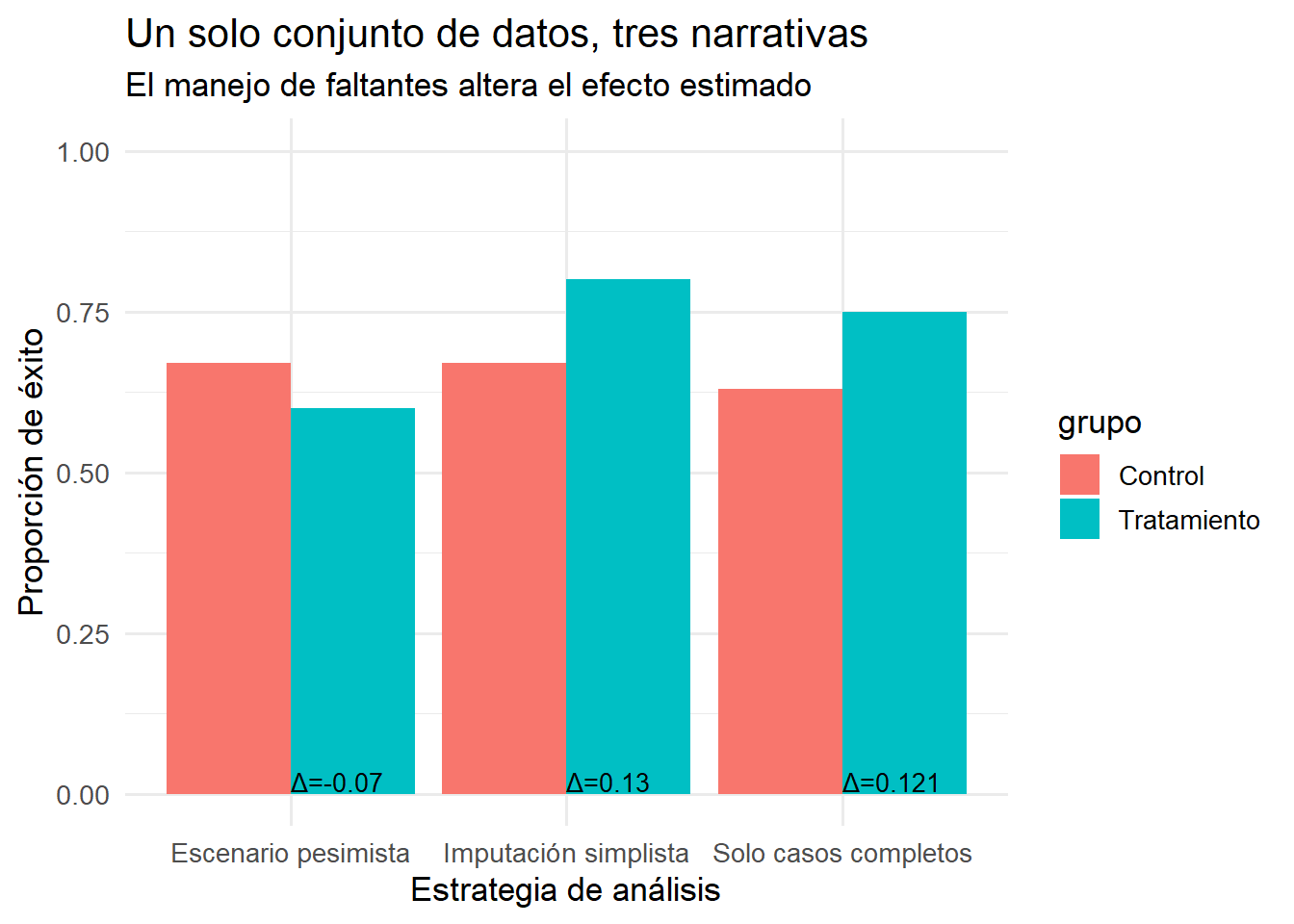
Con los mismos datos:
- un análisis puede exagerar el beneficio,
- otro puede neutralizarlo,
- otro puede invertirlo.
No porque los números “mientan”, sino porque:
cada estrategia introduce un supuesto distinto sobre lo no observado y, por tanto, estima un efecto distinto.
La desconexión no es técnica: es inferencial.
Cómo detectar un Frankenstein en un informe
- ¿La pregunta clínica está formulada explícitamente?
- ¿El estimando está definido (población, variable, sucesos intercurrentes, medida)?
- ¿El análisis corresponde a ese estimando?
- ¿Los datos faltantes están tratados como un problema inferencial, no solo operativo?
- ¿La conclusión depende críticamente de supuestos no discutidos?
Si fallan dos o más, el monstruo probablemente ya esté vivo.
Este post es solo el primer caso
Este ejemplo aborda una sola desconexión:
estimando vs. datos realmente observados (faltantes).
Pero hay otras, igualmente peligrosas:
- fenómeno clínico → objetivo mal formulado
- objetivo → hipótesis irrelevante
- hipótesis → cálculo muestral desalineado
- estimando → método de análisis incoherente
Cada una merece su propio análisis.
Este post funciona como caso 1: datos faltantes dentro de una tipología más amplia de desconexiones inferenciales.
Conclusión
La fragilidad de la evidencia clínica rara vez nace de errores groseros. Más a menudo surge de incoherencias elegantes:
una pregunta clínica, un diseño que se desvía, un análisis que responde otra cosa, y un informe que no distingue entre ambas.
El antídoto no es solo mejor estadística, sino:
- trazabilidad entre pregunta y análisis,
- definición explícita de estimandos,
- análisis de sensibilidad como parte de la evidencia,
- y una lectura crítica que no se conforme con etiquetas.
Bibliografía
- ICH E9(R1) Addendum on estimands and sensitivity analysis. 2019.
- Kahan BC et al. The estimands framework. BMJ. 2024.
- Cro S et al. Choosing estimands in clinical trials. Ther Innov Regul Sci. 2020.
- Ioannidis JPA et al. Methodology over metrics. J Clin Epidemiol. 2021.
- Topol EJ. Failing the public health—rofecoxib. NEJM. 2004.
- Krumholz HM et al. What have we learnt from Vioxx? BMJ. 2007.
Suscripción
Suscríbete a bioestadísticaedu y recibe la serie completa sobre desconexiones inferenciales en ensayos clínicos.
¿Te interesa pensar más allá de los números?
Suscribirse al Boletín en LinkedInRelacionado
- El Frankenstein metodológico: desconexión inferencial entre fenómeno clínico y objetivos o hipótesis
- Cuando la ética se usa para evitar el control
- Rituales metodológicos en ensayos clínicos: cuando la técnica reemplaza al pensamiento
- Ritual ITT/PP en Estudios No Aleatorizados: Desmontando un Mito
- Los siete pecados capitales del protocolo y del Plan de Análisis Estadístico: confesiones de un regulador