Identifica siete errores comunes en protocolos de ensayos clínicos inspirados en pecados capitales para evitar rechazos regulatorios y mejorar la calidad científica.
IMRyD es el estándar de publicación, pero no tiene por qué ser el de redacción. Este post argumenta a favor de una estrategia de escritura 'inversa' —de los hallazgos hacia la introducción— como un método para aumentar la honestidad y claridad, distinguiéndolo del HARKing y alineando la narrativa con el verdadero descubrimiento científico.
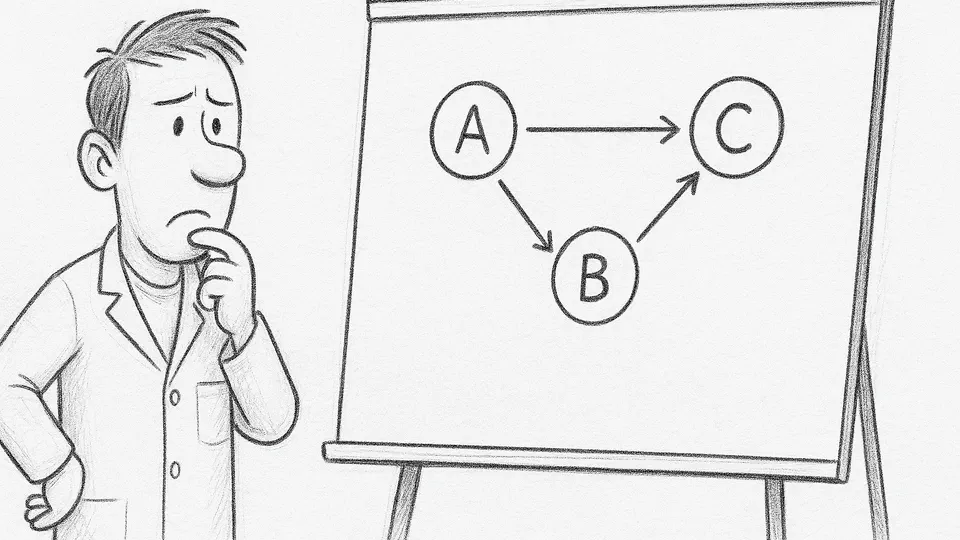
Este blog explora cómo la inferencia causal permite ir más allá de la correlación, aplicando "principios metodológicos" para analizar datos observacionales en salud pública. A partir del desafío de la ausencia del contrafactual, se presentan herramientas avanzadas como el Propensity Score, Diferencias-en-Diferencias y Variables Instrumentales. El enfoque es riguroso, práctico y dirigido a profesionales que buscan complementar la evidencia de los ensayos clínicos.
¿El sagrado p<0.05 es ciencia o solo pirotecnia estadística? Crítica demoledora a la 'significación estadística': sus falacias lógicas, su confusión con la importancia real, y por qué los intervalos de compatibilidad y el enfoque bayesiano son la luz que necesitamos para una investigación más honesta y efectiva.
Por Maicel Monzon Introducción Los ensayos clínicos controlados, aleatorizados y enmascarados (ECAs) constituyen el marco metodológico más robusto para evaluar la eficacia y seguridad de nuevas intervenciones terapéuticas. Son considerados el “estándar de oro” en investigación clínica por agencias como ICH, EMA y FDA, ya que proporcionan el mayor control contra el sesgo y la mayor solidez en inferencia causal.
Por Maicel Monzon Todos conocemos los Modelos de Lenguaje Grandes (LLMs) como ChatGPT de OpenAI, Claude de Anthropic, Gemini de Google y otros modelos similares. Son esos asistentes de IA con los que conversamos, que nos ayudan a escribir correos (Stanford Online 2024)electrónicos, a generar ideas e incluso a codificar.
La ciencia trasciende el laboratorio cuando sus hallazgos logran cruzar el puente hacia la vida real. Este proceso depende de conceptos clave como validez interna (rigor metodológico) y externa (aplicabilidad), así como de la generalizabilidad y transportabilidad de los resultados. Aunque existen obstáculos como sesgos de selección y variables confusoras, herramientas como ensayos pragmáticos y métodos estadísticos permiten adaptar los conocimientos a contextos diversos. Como consumidores, debemos preguntar "¿en quién se hizo este estudio?" para evaluar su verdadero impacto en nuestras vidas.'
El EDA es la fase crítica de inspección y limpieza que garantiza que solo datos de alta calidad alimenten tus algoritmos. Sin un buen EDA, cualquier modelo es propenso al fracaso.
Ejemplos curiosos, cápsulas de rigor y un checklist práctico para no confundir correlación con causalidad en investigación científica.